
Boulder Dash, a VGDL version
of the 1984 computer game
The General Video Game AI Competition (GVG-AI) is a recurring videogame-playing competition intended to stimulate progress in general videogame AI (as distinguished from AI written for a specific game) by testing submitted AI agents against previously unseen videogames. Games used in the competition are written in the Video Game Description Language (VGDL), a domain-specific language designed to capture the type of arcade-style games in which the rules take the form of sprite movement and interaction on a 2d grid. In the current competition, games are all single-player, and may be deterministic or stochastic. The set of unpublished test games on which agents are scored is periodically replaced with a fresh set of games, to keep agents from having the opportunity to even inadvertently become specialized to a specific reused test set. When a new test set is added, the previous one is released publicly. Therefore a corpus of VGDL games has slowly grown, currently at 62 public games.
The 62 VGDL games distributed with the GVG-AI competition framework do represent a specific subset of games—there is nothing here like chess, Starcraft, or even Tetris. But within the style of arcade games that VGDL targets, they cover a fairly wide range of challenges and characteristics, from twitch-type action games to puzzle games, games with NPCs and without, games with counter-based, spatial, or time-based win conditions, and so on. (A feature matrix comparing the first 30 games is given in Table 1 of the paper on the first competition.) This makes the corpus useful as a testbed for investigating differences between algorithms and games.
What I'm interested in here is taking an extended look at the performance scaling of one specific algorithm across this GVG-AI corpus: how the play of "vanilla" Monte Carlo tree search (MCTS) improves, or doesn't, on these 62 games as its computation budget is increased. The goal of doing so is to better understand both sides of the pairing: to use the GVG-AI corpus to look at how MCTS scales with performance across a range of videogames, and also to use the MCTS performance curves as a way of characterizing the nature of the challenges found in the current public set of GVG-AI competition games.
One specific question motivating this scaling experiment was whether
the GVG-AI competition might be too easy. In the first GVG-AI
competition at CIG 2014, the sampleMCTS controller
implementing a vanilla MCTS search, included with the SDK and intended
as baseline, somewhat surprisingly came in 3rd place, achieving a win
rate of about 32%. In the competitions since then it has not done
as well, as both its competitors and the test games have gotten more
challenging; at CEEC 2015 it did particularly badly, placing 31st with
a win rate of only 12%.
The poorer recent results do not entirely dispel the worry about
difficulty. The competition tests agents with only one specific time
limit, 40 milliseconds per move. That leaves open the possibility that
the challenge might be mostly posed by the short time budget. But as
hardware gets faster, and the GVG-AI framework becomes more optimized,
many more MCTS iterations will be possible to complete within the same
40 milliseconds. Profiling suggests that at least an order of magnitude speedup
is likely, because a large portion of the computation time in the
GVG-AI framework's current forward model is taken up by Java
collections bookkeeping that could be avoided. Would the competition then become too
easy, with the sampleMCTS agent making quick work of the
games?
The experiments here find that the answer is no. Performance on
the current corpus of 62 games for the sampleMCTS agent does
improve as computation time is increased from the current limit. But
it plateaus at a win rate of 26% when given about 10x the current
competition's computation budget, and doesn't further improve beyond
that (tested out to around 30x). Therefore we can conclude that even
after an order of magnitude increase in speed of the forward model
(whether through hardware improvements or optimizations), the GVG-AI
competition will still pose challenges requiring something more than
vanilla MCTS to tackle them.
The experiments do however show that as MCTS's computation budget is increased, the way it plays in the games it loses changes considerably. In many of the GVG-AI games, failing to achieve a win within the maximum number of timesteps is a loss. This is in addition to more explicit ways of losing, such as dying due to collision with an enemy. As its computation budget increases, vanilla MCTS manages to avoid most of its explicit losses—only to end up losing via timeout instead. This makes sense if we think of many classic arcade games as consisting of two layers of challenge: avoid dying, and while doing so, achieve a goal. Vanilla MCTS becomes much better at the first challenge as it is given time to perform more iterations, but only slightly better at the second one. This suggests that much of the future challenge in the GVG-AI competition lies in the goal-achievement part; vanilla MCTS can mostly avoid dying, but it often nonetheless can't win.
Aside: Algorithm game-playing performance curves
Besides aiming to verify whether the GVG-AI competition still poses a challenge under a significantly increased computational budget, I'm interested in algorithms' performance scaling curves in their own right.
MCTS is an anytime search algorithm: it has a core iteration loop that can be stopped when it runs out of computation budget, returning the best estimate it has come up with so far. Given more time, it will generally perform better, but existing research has found mixed results regarding what that scaling curve looks like.
Since search trees grow exponentially with depth, there is some heuristic reason to believe that performance will scale with the logarithm of computation time, meaning each doubling of computation time will produce a linear increase in playing strength. This is indeed what some researchers have reported, for example on the game Hex. But other experiments, on Go, have reported diminishing returns with repeated doubling of the computational budget, as performance plateaus rather than continuing to increase linearly. The experiments here are quite different, focusing on a large set of single-player games rather than specific two-player games, but the overall results align more with the second set of experiments on Go, showing diminishing returns eventually reaching a plateau in performance.
Algorithm performance curves have also been used for several other purposes in games, besides the obvious application of playing them. A few years ago, Togelius and Schmidhuber proposed using the performance curve of a genetic algorithm repeatedly playing a game as a fitness function to measure game quality: good games, they hypothesized, are learnable at a moderate pace, leading to mastery neither too quickly nor too slowly. This is a reinforcement learning formulation rather than a planning formulation, so the x-axis of their performance curve is training iterations, rather than time budget as here, but nonetheless the ideas are closely related.
In a slightly different direction, I've been investigating (with collaborators) ratios between different algorithms' performance on a specific game, which we call relative algorithm performance profiles (RAPP), as a game-quality fitness function for evolutionary game generation. This is based on a hypothesis that the strength difference between good and bad agents playing a game can be used as a proxy for game quality, or at least as a filter of bad-quality games: a game on which a random agent performs as well as an agent employing a smarter strategy likely lacks interesting depth. The single-algorithm performance curves I show below can be seen as a generalization of RAPPs to look at not only ratios between algorithms with specific settings (such as random play vs. a specific MCTS configuration), but also curves with parameter variation of a single algorithm. For example, although generating games is not the goal of the experiments here, aspects of an MCTS performance curve, such as whether it's flat versus plateauing early versus plateauing late, may serve as a proxy for depth of at least certain kinds of game challenges.
Back to the experiments.
Methodology
Since I'm investigating the scaling curve of MCTS as its computation budget is increased, the basic methodology is simple: have the agent repeatedly play each game in the GVGAI corpus starting from a small computation budget, then double the computational budget and re-run the same trials on all the games, collecting data as we go along.
I ran tests using a minor variant of the GVG-AI framework, starting from the April 4, 2016 revision in its GitHub repository. I modified the framework to use a limit on MCTS iterations, rather than a time limit, as the method of time budgeting. This change was made in order to make the tests more reproducible. A time limit of, for example, 40 milliseconds or 80 milliseconds per move only produces comparable data if run on exactly the same hardware, with system load and other factors held constant. Since I was running a large number of trials, it was convenient to use cloud-computing resources to carry out the experiments, an environment where it's not possible to assume that every trial will be run on identical hardware with identical system load. A time budget of, for example, 32 or 256 MCTS iterations, on the other hand, is completely reproducible on any hardware. (The reason the GVG-AI competition doesn't go this route is because entrants can submit any kind of agent using any kind of internal strategy, so it has to be treated as a black box and limited only by a time budget.)
As a point of reference to anchor the MCTS iteration counts in this paper with the wall-clock time limit of 40 milliseconds in the GVG-AI competition: I found 40 ms to be enough time to run around 30 MCTS iterations on average, although this varies significantly with the specific game and hardware. Therefore, since the tests here run from 1 through 1024 iterations, they represent a time budget starting at about 1/30 of the current competition's time budget, and going up to about 30x.
The specific implementation of "vanilla" MCTS tested here is the
one included with the GVG-AI SDK as the sampleMCTS
controller. It uses an exploration-exploitation constant of √2 and a play-out depth of
10 moves, with cutoff states evaluated by giving them a large positive
score if a win, large negative score if a loss, and otherwise the
current point value. I chose this controller because it is already
used as a baseline in the GVG-AI competition, widely available to
every GVG-AI competition participant, and has reported competition
results going back several years; therefore what happens to its
performance if the current competition's time budget were
significantly increased serves as a useful baseline. There are of
course many other things about this baseline that could be varied;
here I vary only the number of iterations, not any other parameter
choices, though doing so would be interesting as well.
The GVG-AI game corpus includes 62 games, each of which comes with 5 levels. I run 10 trials of each level, i.e. 50 of each game, for those tests with MCTS iteration limits up to 64, and (to reduce computational resources needed) 5 trials of each level, or 25 per game, for the 128-iteration through 1024-iteration experiments. The difference is visible in the slightly larger error bars on the higher-iteration-count data points in the figures below; the data is otherwise completely comparable. For each of these trials, I recorded whether the outcome was a win or loss, and the number of timesteps to end of game. Games were allowed to run for a maximum of 1000 timesteps. The GVG-AI framework also defines a point score, but I don't use it here, since the MCTS controller is mainly trying to maximize its wins vs. losses rather than playing for points, and comparing points across games is often not very illuminating in any case.
Results
With those preliminaries out of the way, here's what I found. The top-level result is below, plotting win rate (across all trials of all games) versus MCTS iteration limit. This shows a rapid increase in win rate initially, as the iteration limit is increased from its very low starting point of 1, followed by dimishing returns up towards a plateau of about 26% past the 256-iteration trials. Error bars represent 95% confidence intervals, estimated via a nonparametric bootstrap.
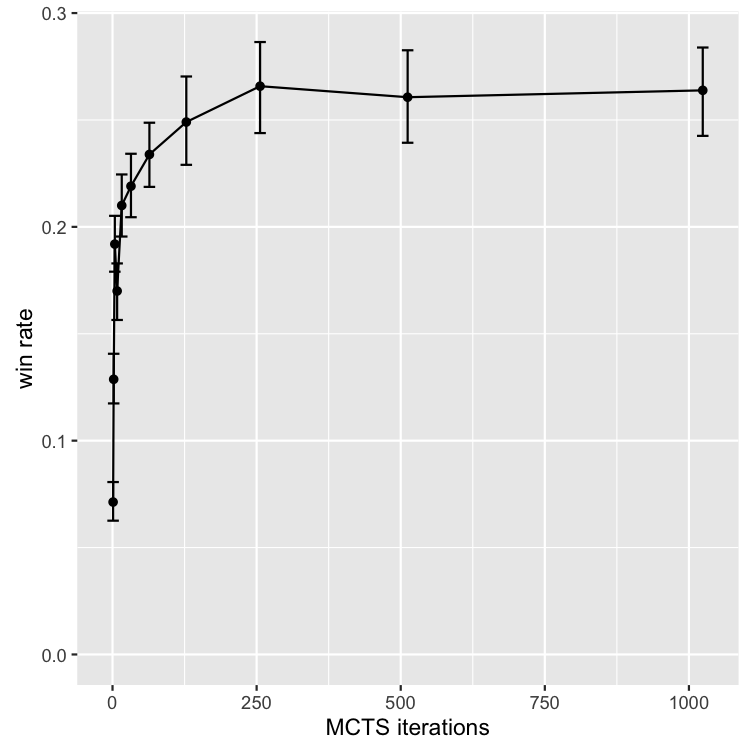
Below, plotting the win-rate curve on a logarithmic x axis gives a more detailed look at the scaling properties. The general expectation that MCTS should scale logarithmically with increased iterations is partly confirmed: the scaling does look logarithmic, i.e., linear on the log-axis graph, up until the plateau past 256, although with some anomalies. There is a higher slope from 1-4, followed by a lower slope from 16 to 256, interrupted by a strange but significant dip in performance at 8. The reason for this dip is not entirely clear, but as we'll see in a minute is visible across a number of specific games as well.
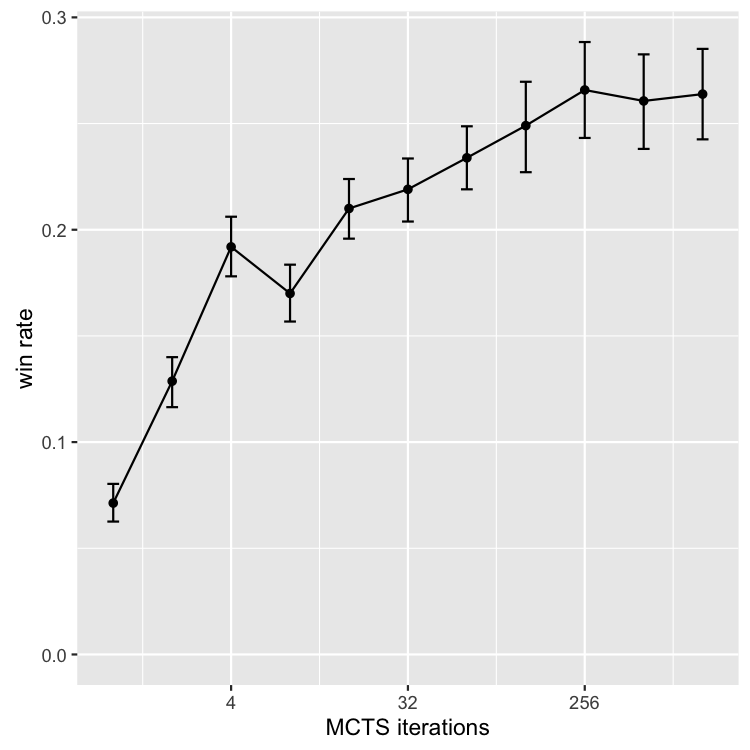
The main takeaway from the top-level results is that overall
performance of the sampleMCTS agent would improve if the
GVG-AI competition's time budget allowed for more than the current 30
or so MCTS iterations, either through increasing time budget or (more
likely) optimizing the rollout code. But, not indefinitely, and
not by that much: from around 22% to 26% overall win rate. Therefore,
my initial hypothesis that the GVG-AI competition's challenge might
be somewhat illusory, due mainly to the small time budget and
unoptimized code, is not confirmed: the baseline sampleMCTS
agent would not start dominating the competition even if its time
budget were increased by 10x+. And based on the clear plateau in
performance, it is unlikely to do so even if it were given still more
time than that.
Types of wins and losses
While running these experiments, I noticed that experiments with higher iteration limits were taking much longer to complete, by more than would be expected just from the increased number of MCTS iterations. Investigating further, the reason appears to be that when given more computation time, the MCTS agent plays much longer games. And specifically, its losses drag out for longer, while its wins stay at about the same length:
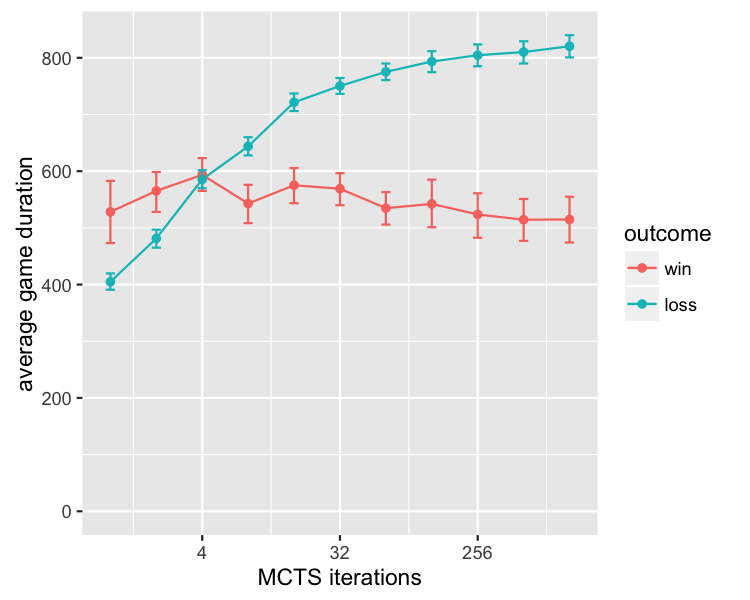
In fact not only is the MCTS agent playing longer games in its losses as its time budget increases, but an increasing proportion of losses come right at the maximum length limit of 1000 timesteps. This suggests that significant qualitative changes of play are taking place that are somewhat masked what looking only at the win-rate results (since long losses and short losses are still losses). One way of making these changes more visible in the overall results is to change from scoring games on a 2-outcome scale of win/loss, to a 3- or 4-outcome scale that treats timeouts when the maximum game length is reached differently.
The graphs below reinterpret the overall win-rate data using two alternate ways of treating timeouts. In the first one, 3-outcome scoring is used, with games resulting in either a win (within time), a loss (within time), or a timeout, treated as different from either a win or loss. From this it can be seen that while wins slowly increase, the biggest swing in overall performance is that, given more computation time, the MCTS agent manages to convert losses into timeouts. In the second one, timeouts are further broken down into wins at timeout and losses at timeout, which shows that the biggest swing is specifically from losses within time, to losses at timeout.
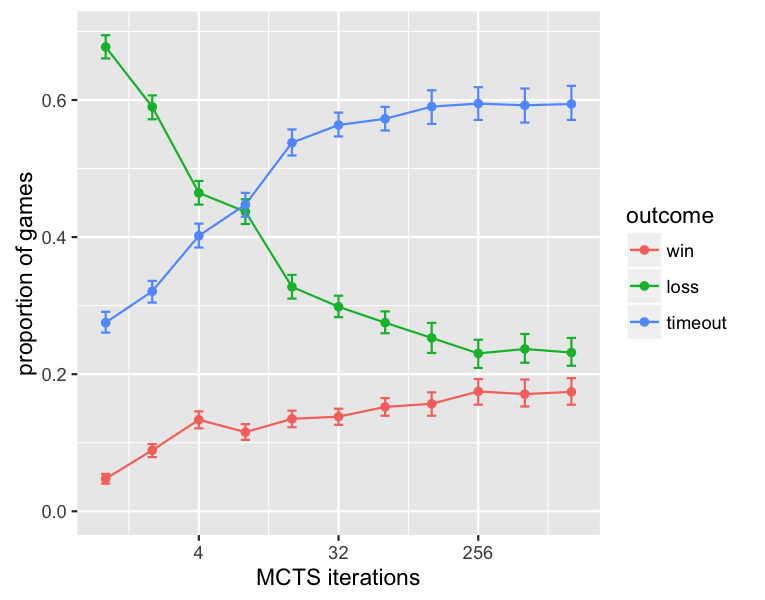
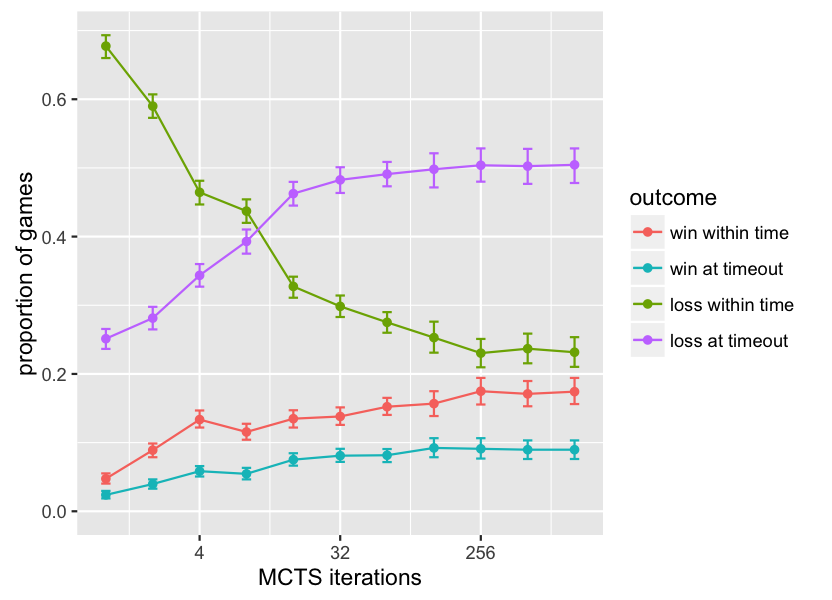
From this view of the data, the MCTS agent can actually be said to come close to mastering the GVG-AI games if the goal were not to lose, with timeouts treated as non-losses: while its win rate plateaus at a not-that-impressive 26%, it brings its overall loss-within-time rate down to a mere 22%, i.e. it manages to avoid explicitly losing (except by timeout) in 78% of games. This quite large gap in two ways of looking at what constitutes good performance leads to a hypothesis that the current GVG-AI competition has two distinct types of challenges, and a vanilla MCTS agent can master one but not the other: first, avoid losing, and then, figure out how to win.
Why winning is apparently much harder than not losing within time is not entirely clear; it may be that in most of the GVG-AI games, winning requires a more complex policy than avoiding explicit losses does; for example, avoiding explicit losses in some of the games requires short-term reactive behavior such as avoiding an enemy, while winning requires putting together a sequence of steps to achieve a goal. It also suggests that the choice of whether a GVG-AI game should result in a win or loss at timeout has a significant effect on the challenge posed; most GVG-AI games result in a loss at timeout.
The different insight into performance given by looking at only wins and losses, versus treating timeouts separately, leads me to propose that future analyses of algorithm performance on the GVG-AI corpus may want to report both measures, in order to provide a fuller view of the algorithm's playing strengths and weaknesses.
Per-game results
The table below breaks the results down for each of the 62 games, showing win rate, represented by brightness of the table entry, as MCTS iterations increase. The table is ordered from top to bottom by the sum of win rates across all trials for that game, i.e. games at the top are overall won by the MCTS agent more often than those at the bottom.
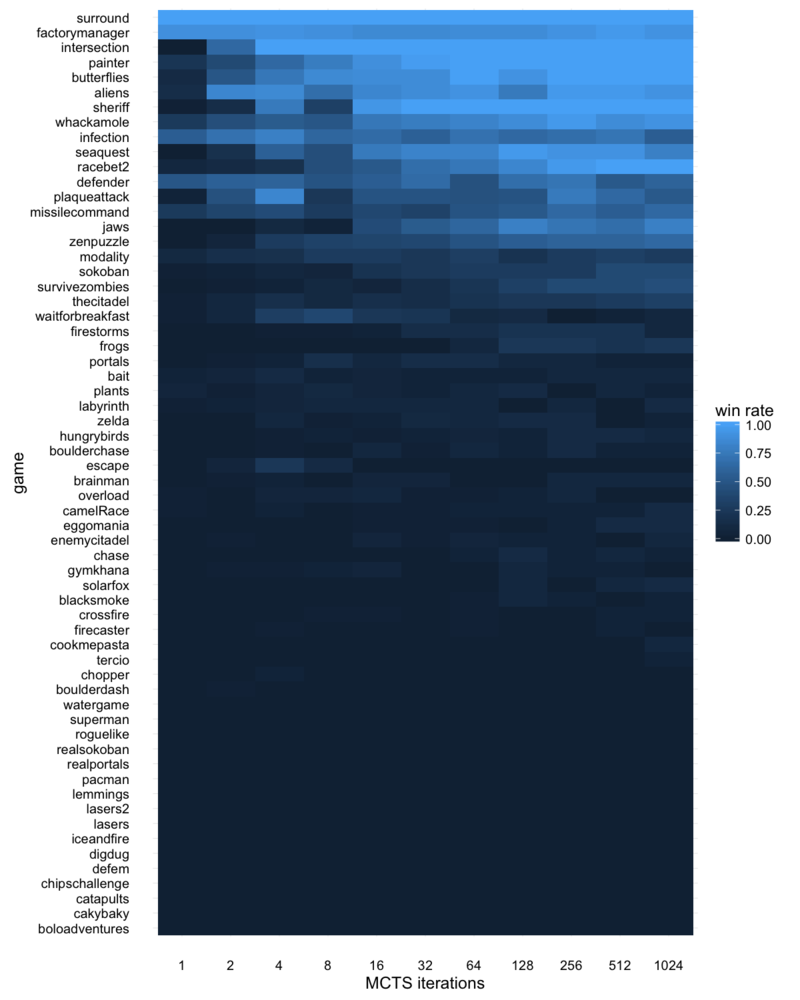
A few noticeable aspects are worth pointing out. First, a relatively
small number of games, about a dozen, are the only ones that really
differentiate performance of the lower-iteration and higher-iteration
MCTS agents. Most games are insensitive to iterations: in more than
half, the MCTS agent rarely wins, regardless of time budget, and in a
few, it mostly wins even with small time budgets. Only a few games,
such as seaquest and racebet2, seem to present the
MCTS agent with a difficulty curve, where it performs better as it
computes more. And a few games are completely mastered with increasing
iterations: the most stark cliff is for intersection, which
reaches an 100% win rate at mere 4 iterations, but is not so easy
that it can be mastered with only 1 or 2 iterations. The odd decrease
in performance at 8 iterations observed in the overall results can
also be seen in a number of individual games here, such as
plaqueattack and sheriff.
The rather few number of games that show performance differentiation has implications for uses of algorithm performance profiles as a fitness function in game generation (discussed above in the Aside). Algorithm performance profiles are only a meaningful stand-in for difficulty curves or challenge depth if we can blame a lack of performance differentiation in a specific game between an algorithm and random play on the game rather than the algorithm. The many GVG-AI games on which vanilla MCTS fails to achieve any win rate at all implies it may not be a great candidate for use in such fitness functions, since it will reject many games which do have challenge depth but which it is simply not able to play.
* * *
Scaling the baseline MCTS controller used in the GVG-AI competition from about 1/30 of the current competition's time budget through about 30x of the current competition's time budget finds that performance initially increases roughly with the logarithm of increased computation time, although with some anomalies in the slope, up to a plateau at around 256 MCTS iterations, after which performance does not increase further. The plateau implies that even massive amounts of computational power would be insufficient to solve the challenges in the current competition using the baseline MCTS agent. This may be due to the 10-depth cutoff in the Monte Carlo rollouts, or it may be due, as Perez et al. hypothesize, to suboptimal estimates produced by closed-loop MCTS on stochastic games.
My initial skeptical hypothesis that the GVG-AI competition might not pose much medium-term challenge in the face of performance improvement is therefore not confirmed. Performance plateaus past 256 MCTS iterations, which is roughly 10x the time budget of the current GVG-AI competition, and furthermore plateaus at only a 26% win rate. Therefore the GVG-AI competition would remain interesting, at least relative to the current baseline, even if orders of magnitude more computation time were given to the agents entering the competition.
I do however find that quite a lot of change in gameplay is happening beneath the headline win-rate data. As time budget is increased, MCTS takes longer to lose the games that it's going to lose. And, it often loses them in a qualitatively different way, by hitting the maximum game length (which in many GVG-AI games is a loss through timeout), rather than succumbing to one of the explicit loss conditions, such as colliding with an enemy. When the overall results are reinterpreted using a 3-valued outcome of win, loss, or timeout, the vanilla MCTS agent does manage to avoid losses in the majority of games, at the larger time budgets, bringing its "non-loss" rate up to 78%—much more impressive than its 26% win rate—with the majority of games ending in a timeout.
This suggests two conclusions. First, it may be helpful to look beyond the headline win rate in the GVG-AI competition when comparing agents, and treat games that timeout differently from those where a win or loss is recorded within time. This provides a fuller view of what the agent is doing, and which kinds of challenges it is succeeding or failing at. Secondly, it suggests that in the current corpus of GVG-AI games, the challenge is structured so that not-losing is easier than winning. Further research is needed to help clarify why this is. For example, it may be that in the majority of the games a relatively simple controller can avoid losing, perhaps with even a very simple reactive policy like "move away from enemies", but more complex planning may be needed to achieve win conditions. One approach to confirming whether this is the case could be to solve for optimal policies for several of the games and investigate their structure.
Future work should look at more algorithms beyond the one baseline whose scaling properties I tested here. I varied only the time budget in the baseline MCTS controller, but there are many variations of MCTS and quite a few other parameters that can be varied. MCTS can also be compared on this corpus with the scaling of other algorithms, such as traditional full-width search.
Published version: Mark J. Nelson (2016). Investigating vanilla MCTS scaling on the GVG-AI game corpus. In Proceedings of the 2016 IEEE Conference on Computational Intelligence and Games.